Automated Election of Leader Instances in AWS Autoscaling Groups
Hey there, people!
We wanted to share with you a solution we recently discovered that describes leader election in AWS autoscaling groups. This might be new learning (at least, it was for us). So hang on, we promise this should be interesting.
What is a leader election?
Here is an article that describes leader election from a general standpoint. It describes leader election as the simple idea of giving one thing (a process, host, thread, object, or human) in a distributed system some special powers.
The Problem
One of our apps that was deployed using the AWS Elastic Beanstalk service was receiving increased load and sudden spikes in traffic. This came with downtime impacting customer experience, especially during peak hours. We realized that due to increased scaling events, app logic needing to be implemented by only one instance at one given time was erratic.
Thus, to improve the scalability of the deployed application and meet increasing demand without compromising performance, the leader selection process had to be automated.
Why would you want to do this?
Imagine you have a group of machines that are all capable of performing a critical task. However, to avoid errors, only one of the machines should perform this task at a time. Congratulations, you have found a great use case for leader election!
Some real-life examples might be scheduled jobs, in situations where those jobs cannot be run in parallel, or in applications where multiple instances need to interact with a database, leader election ensures that only one instance is responsible for executing database transactions at any given time.
The Solution
To bring order to our scaling environment, we looked for ways to use AWS native services. We found an article that addressed our problem and used its solution as a starting point. We then explored newer AWS services and worked to improve the solution. Our approach involved building a leader election solution using Terraform, Lambda (Python), and Eventbridge to automate the leader selection process. You can check out the code in our project repo.
Steps
To fully follow along with this project, ensure that you have all the following necessary prerequisites set up correctly.
Prerequisites:
- You should have an AWS account with sufficient permissions to create IAM roles, Lambda functions, and Autoscaling groups.
- Terraform 0.12+ or AWS CLI installed on your local machine, depending on which deployment method you choose.
- Basic knowledge of AWS services, and IAC tools like Terraform.
- Finally, this project assumes that you already have an Elastic Beanstalk environment. Ideally, your EB environment contains an Autoscaling group managing the instances that your application is run on.
Getting these prerequisites set is easy. I believe in you figuring them out if you haven’t already.
Now, to the project:
- Get the code. Clone the code for this project from the repo.
❯ git clone https://github.com/JayNoblez/aws-asg-leader-election-enhanced.git2. Run the following command to initialize Terraform:
terraform initInitializing the backend...
Initializing provider plugins...
- Finding latest version of hashicorp/aws...
- Finding latest version of hashicorp/random...
- Finding latest version of hashicorp/archive...
- Installing hashicorp/aws v4.56.0...
- Installed hashicorp/aws v4.56.0 (signed by HashiCorp)
- Installing hashicorp/random v3.4.3...
- Installed hashicorp/random v3.4.3 (signed by HashiCorp)
- Installing hashicorp/archive v2.3.0...
- Installed hashicorp/archive v2.3.0 (signed by HashiCorp)
Terraform has created a lock file .terraform.lock.hcl to record the provider
selections it made above. Include this file in your version control repository
so that Terraform can guarantee to make the same selections by default when
you run "terraform init" in the future.
Terraform has been successfully initialized!3. Run the following command to preview Terraform's changes to your infrastructure before actually applying them.
terraform plan
Terraform used the selected providers to generate the following execution plan. Resource actions are indicated with the following symbols:
+ Create
<= read (data resources)
Terraform will perform the following actions:
# data.archive_file.packaged_lambda will be read during apply
# (config refers to values not yet known)
<= data "archive_file" "packaged_lambda" {
+ id = (known after apply)
+ output_base64sha256 = (known after apply)
+ output_md5 = (known after apply)
+ output_path = (known after apply)
+ output_sha = (known after apply)
+ output_size = (known after apply)
+ source_dir = "./lambda"
+ type = "zip"
}
# aws_cloudwatch_event_rule.scaling_event_rule will be created
+ resource "aws_cloudwatch_event_rule" "scaling_event_rule" {
+ arn = (known after apply)
+ description = "Rule for scaling event in elastic beanstalk autoscaling group awseb-"
+ event_bus_name = "default"
+ event_pattern = jsonencode(
{
+ detail = {
+ AutoScalingGroupName = [
+ {
+ prefix = "awseb-"
},
]
}
+ detail-type = [
+ "EC2 Instance Launch Successful",
+ "EC2 Instance Terminate Successful",
+ "EC2 Instance Launch Unsuccessful",
+ "EC2 Instance Terminate Unsuccessful",
+ "EC2 Instance-launch Lifecycle Action",
+ "EC2 Instance-terminate Lifecycle Action",
]
+ source = [
+ "aws.autoscaling",
]
}
)
+ id = (known after apply)
+ is_enabled = true
+ name = "asg-leader-election-scaling-event-rule"
+ name_prefix = (known after apply)
+ tags_all = (known after apply)
}
# aws_cloudwatch_event_target.lambda_target will be created
+ resource "aws_cloudwatch_event_target" "lambda_target" {
+ arn = (known after apply)
+ event_bus_name = "default"
+ id = (known after apply)
+ rule = "asg-leader-election-scaling-event-rule"
+ target_id = "lambda_target"
}
# aws_iam_role.lambda will be created
+ resource "aws_iam_role" "lambda" {
+ arn = (known after apply)
+ assume_role_policy = jsonencode(
{
+ Statement = [
+ {
+ Action = "sts:AssumeRole"
+ Effect = "Allow"
+ Principal = {
+ Service = "lambda.amazonaws.com"
}
},
]
+ Version = "2012-10-17"
}
)
+ create_date = (known after apply)
+ force_detach_policies = false
+ id = (known after apply)
+ managed_policy_arns = (known after apply)
+ max_session_duration = 3600
+ name = "asg-leader-election-lambda-role"
+ name_prefix = (known after apply)
+ path = "/"
+ tags_all = (known after apply)
+ unique_id = (known after apply)
+ inline_policy {
+ name = (known after apply)
+ policy = (known after apply)
}
}
# aws_iam_role_policy.lambda will be created
+ resource "aws_iam_role_policy" "lambda" {
+ id = (known after apply)
+ name = "asg-leader-election-lambda-role-policy"
+ policy = jsonencode(
{
+ Statement = [
+ {
+ Action = [
+ "ec2:Describe*",
+ "ec2:*Tags",
]
+ Effect = "Allow"
+ Resource = [
+ "*",
]
},
+ {
+ Action = [
+ "logs:CreateLogGroup",
+ "logs:CreateLogStream",
+ "logs:PutLogEvents",
+ "logs:DescribeLogStreams",
]
+ Effect = "Allow"
+ Resource = [
+ "arn:aws:logs:*:*:*",
]
},
+ {
+ Action = [
+ "ec2:DescribeAvailabilityZones",
+ "ec2:DescribeInstances",
+ "autoscaling:DescribeAutoScalingGroups",
+ "autoscaling:DescribeAutoScalingInstances",
+ "autoscaling:DescribeTags",
+ "s3:ListMyBuckets",
]
+ Effect = "Allow"
+ Resource = [
+ "*",
]
},
]
+ Version = "2012-10-17"
}
)
+ role = (known after apply)
}
# aws_lambda_function.leader will be created
+ resource "aws_lambda_function" "leader" {
+ architectures = (known after apply)
+ arn = (known after apply)
+ description = "Elects a leader in an autoscaling upon receiving scaling events"
+ filename = (known after apply)
+ function_name = "asg-leader-election"
+ handler = "index.lambda_handler"
+ id = (known after apply)
+ invoke_arn = (known after apply)
+ last_modified = (known after apply)
+ memory_size = 128
+ package_type = "Zip"
+ publish = false
+ qualified_arn = (known after apply)
+ qualified_invoke_arn = (known after apply)
+ reserved_concurrent_executions = -1
+ role = (known after apply)
+ runtime = "python3.8"
+ signing_job_arn = (known after apply)
+ signing_profile_version_arn = (known after apply)
+ source_code_hash = (known after apply)
+ source_code_size = (known after apply)
+ tags_all = (known after apply)
+ timeout = 30
+ version = (known after apply)
+ ephemeral_storage {
+ size = (known after apply)
}
+ tracing_config {
+ mode = (known after apply)
}
}
# aws_lambda_permission.eventBridge will be created
+ resource "aws_lambda_permission" "eventBridge" {
+ action = "lambda:InvokeFunction"
+ function_name = (known after apply)
+ id = (known after apply)
+ principal = "events.amazonaws.com"
+ source_arn = (known after apply)
+ statement_id = "AllowExecutionFromEventBridge"
+ statement_id_prefix = (known after apply)
}
# random_uuid.lambda_src_hash will be created
+ resource "random_uuid" "lambda_src_hash" {
+ id = (known after apply)
+ keepers = {
+ "index.py" = "7a19e5745fb7e370fc558f8e8ee827c8"
}
+ result = (known after apply)
}
Plan: 7 to add, 0 to change, 0 to destroy.4. Finally, run the following command to deploy the previewed resources in step 3 into your AWS account.
terraform applyVoila!
With Terraform, you have successfully created resources such as a Cloudwatch event rule to monitor scaling events in your autoscaling group, a Lambda function, and an IAM role and policy to enable the Lambda function to access required AWS resources.

Now, any Autoscaling scaling Group events in your infrastructure will trigger a rule that, in turn, triggers a lambda function to elect the leader instance and update a tag on that instance, indicating that it is the current leader.
resource "aws_cloudwatch_event_rule" "scaling_event_rule" {
name = "${var.name}-scaling-event-rule"
description = "Rule for scaling event in elastic beanstalk autoscaling group ${var.asg_name_prefix}"
event_pattern = jsonencode({
source = ["aws.autoscaling"]
detail-type = ["EC2 Instance Launch Successful",
"EC2 Instance Terminate Successful",
"EC2 Instance Launch Unsuccessful",
"EC2 Instance Terminate Unsuccessful",
"EC2 Instance-launch Lifecycle Action",
"EC2 Instance-terminate Lifecycle Action"]
detail = {
AutoScalingGroupName = [{ prefix = var.asg_name_prefix }]
}
})
}But how does the Lambda function choose which instance should be the leader? The function considers factors like instance availability, performance metrics, and even randomness. Once the function selects a leader, it updates a tag on the instance so that other machines know not to attempt to become the leader.
# if there's already a leader, don't change anything.
if len(leaders) == 1:
print(f"Retaining leader instance {leader_instance_ids[0]}")
return json.loads(json.dumps(leaders[0], default=str))
# if there is more than one leader, keep one of them.
elif len(leaders) > 1:
new_leader = leader_instance_ids[0]
# if there are no leaders and the triggering instance is coming online, make it the leader.
elif "Launching a new EC2 instance:" in event_detail['Description']:
new_leader = event_detail['EC2InstanceId']
# Otherwise, just pick a leader.
else:
new_leader = candidates[0]Automatic instance tagging in action
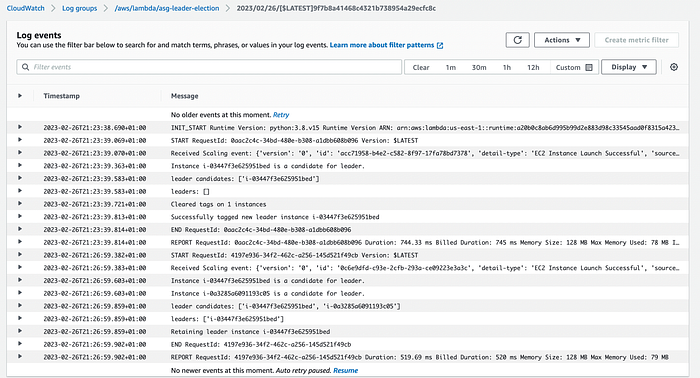
You can now confirm from checking the Cloudwatch logs that even though both instances in the autoscaling group are capable of being elected as leader, only one eventually receives this designation.
leader candidates: ['i-03447f3e625951bed', 'i-0a3285a6091193c05']
leaders: ['i-03447f3e625951bed']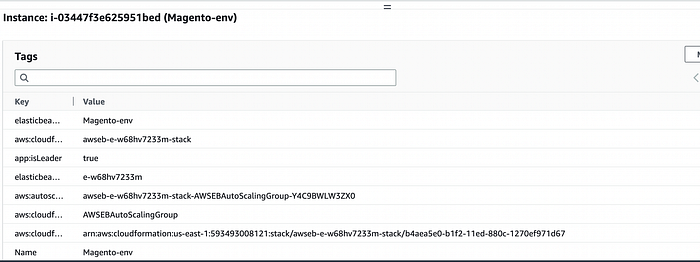
The instance is tagged appropriately with the tag app:isLeader = True.
In conclusion, we found the solution to be simple and efficient in catering to the fault tolerance needed by the application.
Where high availability is critical, leader election can be used to ensure that if the current leader instance fails, a new leader is elected quickly and automatically, thus helping your next ASG project minimize downtime, and ensure that the system continues to operate correctly.
We hope you enjoyed the project. Please give us a clap if you did! Thank you!
Till next time, from your community builders.
Written by John Adedigba & Ahiwe Onyebuchi Valentine — Feb, 2023
